简介
2015年毕业设计,开发了一个Chrome扩展应用,在被试的新浪微博浏览页面生成假的朋友微博或网络红人微博来向其推荐一款虚拟现实眼镜。通过收集被试的行为数据来检验推荐效果。最终结果简而言之是对于个人来说,朋友的短期推荐效果远好于网红。 扩展应用用到了一些JavaScript、HTML、JQuery,同时建了一个服务器和扩展应用交换数据并存储数据。 |Github项目传送门|
实验描述
猜想:朋友的推荐效果好于知名博主的效果
在决定实验任务的时候会做一个合理的假设:所有实验参加者都有丰富、频繁地使用新浪微博的经验,并且关注的知名博主和朋友的微博数各超过5个。在招募实验人员时会将这些条件作为限制,具体要求每周浏览次数大于等于2,知名博主粗略定义为粉丝数大于等于10万的个人微博。 参试者每天按照自身习惯在电脑终端上浏览若干分钟微博,其中包含一条实验伪造推送的商品微博,总共浏览5天。所有推送的商品微博都具有相同的内容、图片和链接等元素,唯一的不同就是由不同的博主推送。
为了验证猜想,至少需要2组进行检测,考虑到用户类型混合进行推送可能更合理,因此最终设计了4组:
- 组1:完全由5名朋友分5天推送商品微博
- 组2:先由1名知名博主推送,然后4名朋友分别推送商品微博
- 组3:先由1名朋友推送,然后4名知名博主分别推送商品微博
- 组4:完全由5名知名博主推送商品微博
参试者会被随机分配到四个组中,不过考虑到涉入度的影响,会按高中低三个水平的涉入程度进行调整,尽可能使各组的高中低涉入的参试者比例相同。
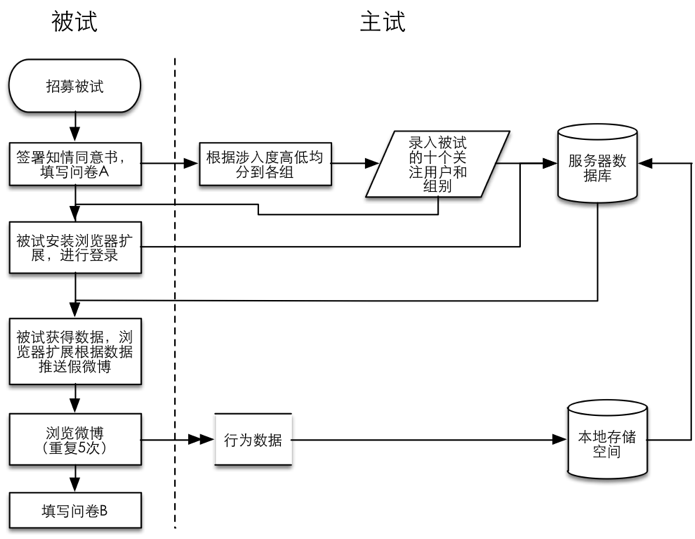
在整个实验中,参试者们会被要求在自己的电脑上安装Chrome浏览器,并安装为了实验开发的浏览器插件。通过插件用被试ID登录后,打开微博浏览页面即会弹出是否开始当天实验任务的提示。点击开始后即可进行实验,按自身习惯进行浏览即可,并要求至少浏览完第一页才能刷新页面结束当天的实验任务。除此之外,并无任何对参试者浏览的干扰,保证了参试者是在尽可能自然的状态进行浏览,避免发觉有伪装的微博混入,察觉实验目的而影响其真实的行为。
每一次实验任务中,会在被试提供的5名知名博主和5名朋友中随机、不重复地选出一名博主,然后伪造一条由这名博主推送的智能眼镜的微博,如图1所示。

每个被试每天收到的伪造微博都是相同的,包含一条商品链接和一幅智能眼镜的图片。商品链接也是链接到一个伪造的商品页面。如图2所示:

商品页面中具有简单的商品介绍,和“想买”、“关注”、“购买”三个按钮用以探查参试者的反应。这三个按钮的点击行为也会被浏览器插件所捕捉。 在实验前我们会告知被试正常按照个人习惯浏览微博即可,没有时间限制,但要求至少浏览完第一页才能结束实验。同时告知实验会记录他们浏览微博的操作行为。
整个实验的流程如下图:
 简单地解释下其中“涉入度”的概念,代表你对这个商品或品牌本身的感兴趣程度和了解程度,数值越大表示越感兴趣、越了解。
简单地解释下其中“涉入度”的概念,代表你对这个商品或品牌本身的感兴趣程度和了解程度,数值越大表示越感兴趣、越了解。
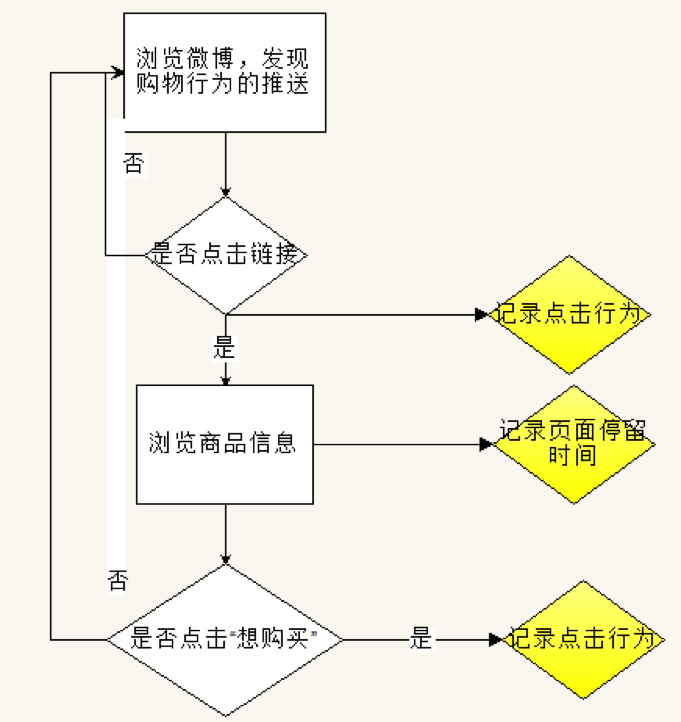
每一次小的浏览任务流程如下图:
技术实现
Weibo Spider
要生成假微博,就需要先分析一条微博里面由哪些信息构成:微博的信息和微博主的信息
虽然还有转发类型的微博,但是我们目标制作的假微博并不使用转发形式。
微博的信息可以编造为固定内容,但是微博主的信息是变化的,如何让微博主的头像、名称、链接显示为我们想要展示的呢?
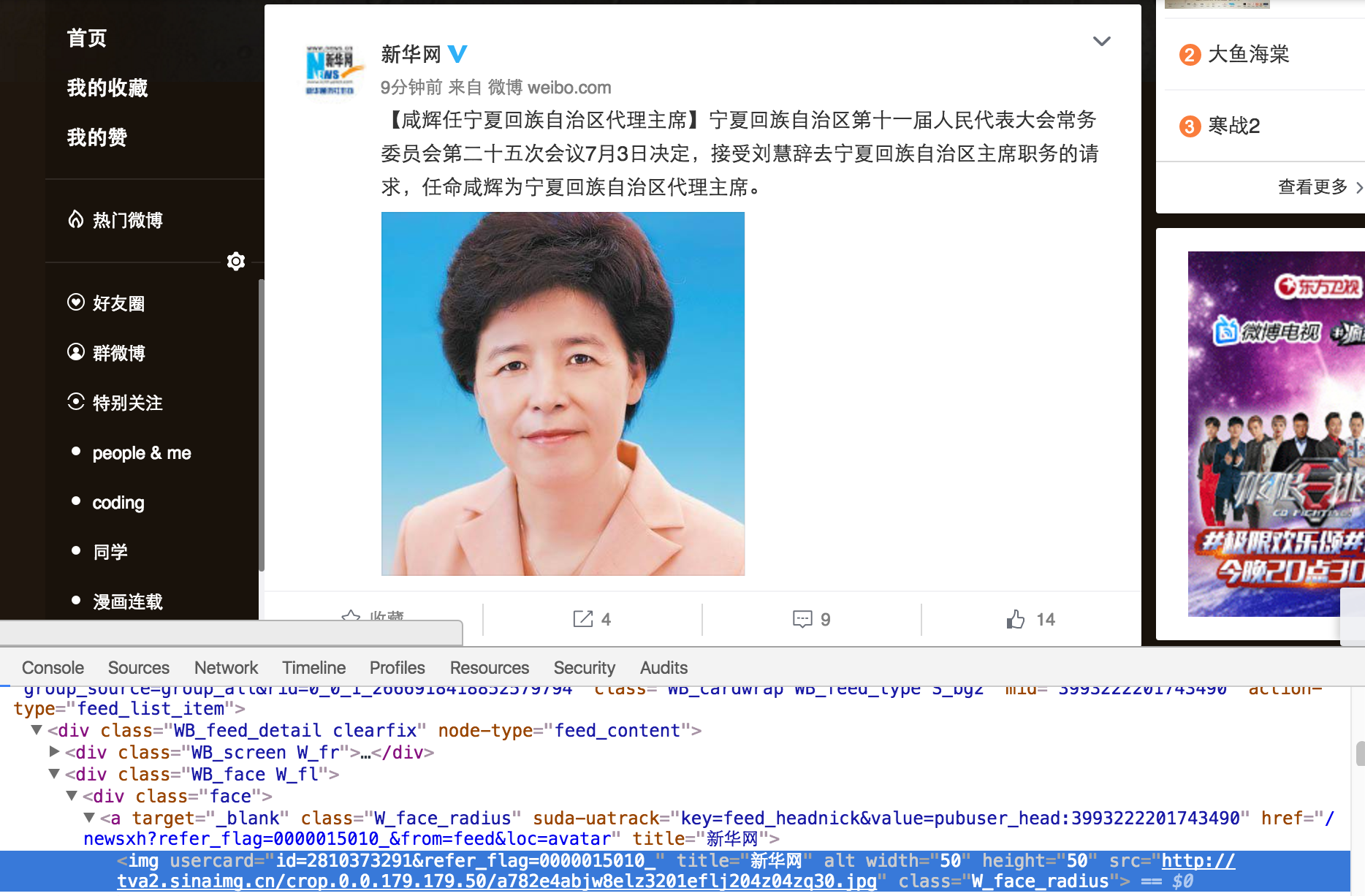 虽然没专门学过html,但稍有常识的人即可看出(Θ..Θ),只要改了usercard、title、src三个属性就可以把头像图片、链接、title都改了。如下图:
虽然没专门学过html,但稍有常识的人即可看出(Θ..Θ),只要改了usercard、title、src三个属性就可以把头像图片、链接、title都改了。如下图:
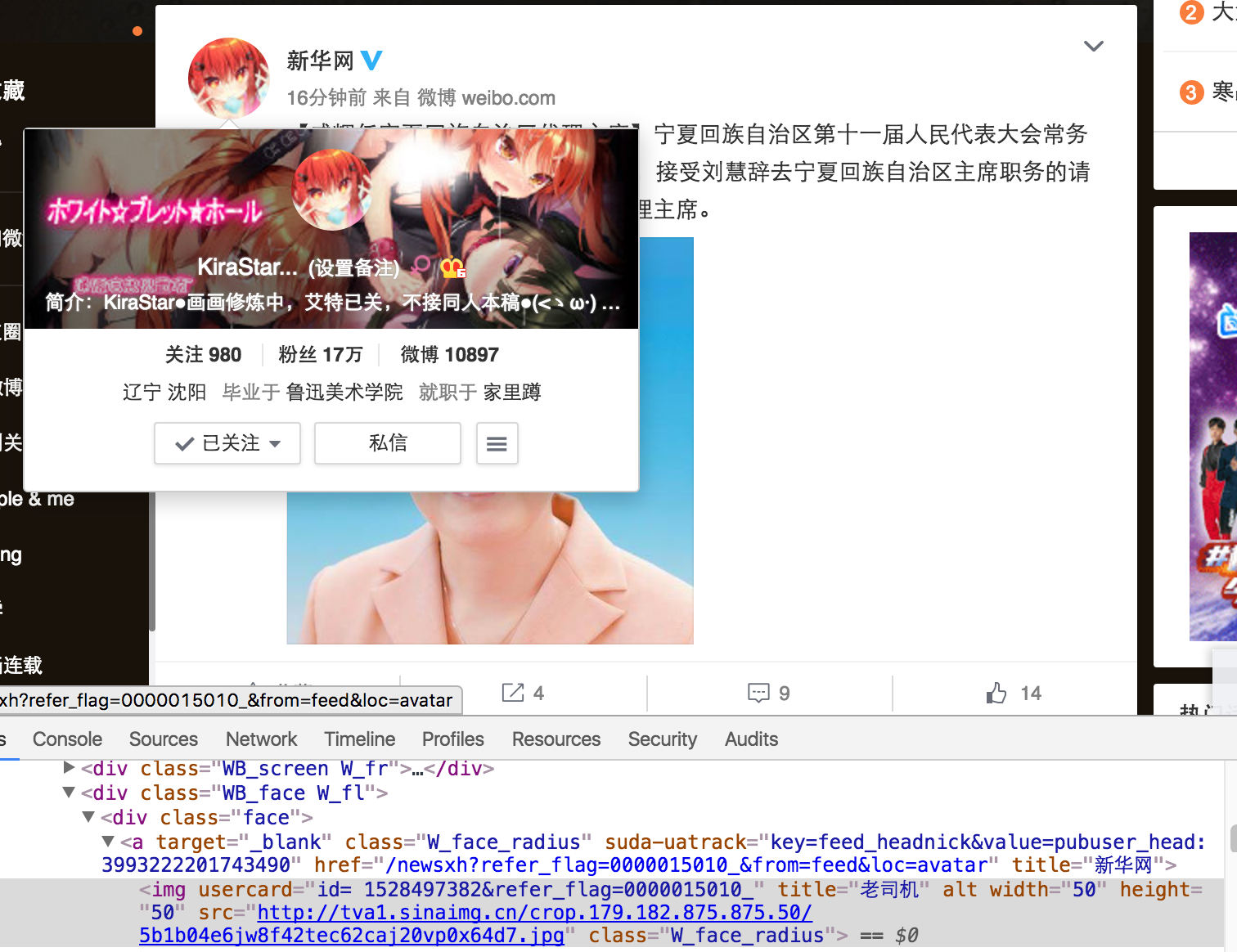
因此我们需要从博主的页面抓取一些内容,比如ID号、微博名等。虽然在问卷调研时让被试填写了十个博主,但是考虑到被试并不懂相关知识,只让他们填写了博主的名称和URL地址,方便我写爬虫抓取我要的内容。
为了读取excel文件,需要先安装xlrd包,easy_install xlrd或者pip install xlrd,记得换国内镜像或者开VPN,否则就会time out。
这一部分主要的障碍是微博的登录,只有登录了才能看到微博博主的内容。而早在跟老师做SRT项目时,指导我们的学姐的毕业设计就是微博语义分析来预测传染病爆发。当时学姐使用的是微博应用的SDK,但是会限制每天的流量或是读取的用户数(具体记不清了)。 而这个项目只需要读一遍用户主页抓微博名、ID,并不需要成本这么高的做法,学习并解析weibo.com的js来编写适用的代码。因此在网上找到了weibo.cn模拟登录的代码(链接)。 weibo.com和weibo.cn的区别在于后者几乎没有什么js,加载的内容全在html中。
#! /usr/bin/env python
# -*- coding: utf-8 -*-
import re
import urllib
import urllib2
import cookielib
import lxml.html as HTML
class Fetcher(object):
def __init__(self, username=None, pwd=None, cookie_filename=None):
#获取一个保存cookie的对象
self.cj = cookielib.LWPCookieJar()
if cookie_filename is not None:
self.cj.load(cookie_filename)
#将一个保存cookie对象,和一个HTTP的cookie的处理器绑定
self.cookie_processor = urllib2.HTTPCookieProcessor(self.cj)
#创建一个opener,将保存了cookie的http处理器,还有设置一个handler用于处理http的URL的打开
self.opener = urllib2.build_opener(self.cookie_processor, urllib2.HTTPHandler)
#将包含了cookie、http处理器、http的handler的资源和urllib2对象绑定在一起
urllib2.install_opener(self.opener)
self.username = username
self.pwd = pwd
self.headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; rv:14.0) Gecko/20100101 Firefox/14.0.1',
'Referer':'','Content-Type':'application/x-www-form-urlencoded'}
def get_rand(self, url):
headers = {'User-Agent':'Mozilla/5.0 (Windows;U;Windows NT 5.1;zh-CN;rv:1.9.2.9)Gecko/20100824 Firefox/3.6.9',
'Referer':''}
req = urllib2.Request(url ,"", headers)
login_page = urllib2.urlopen(req).read()
rand = HTML.fromstring(login_page).xpath("//form/@action")[0]
passwd = HTML.fromstring(login_page).xpath("//input[@type='password']/@name")[0]
vk = HTML.fromstring(login_page).xpath("//input[@name='vk']/@value")[0]
return rand, passwd, vk
def login(self, username=None, pwd=None, cookie_filename=None):
if self.username is None or self.pwd is None:
self.username = username
self.pwd = pwd
assert self.username is not None and self.pwd is not None
url = 'http://login.weibo.cn/login/?rand=437560244&backURL=http%3A%2F%2Fweibo.cn%2F&backTitle=%E5%BE%AE%E5%8D%9A&vt=4&revalid=2&ns=1'
# 获取随机数rand、password的name和vk
rand, passwd, vk = self.get_rand(url)
print(rand, passwd, vk)
data = urllib.urlencode({'mobile': self.username,
passwd: self.pwd,
'remember': 'on',
'backURL': 'http://weibo.cn/',
'backTitle': '新浪微博',
'vk': vk,
'submit': '登录',
'encoding': 'utf-8'})
url = 'http://login.weibo.cn/login/' + rand
print url
# 模拟提交登陆
page =self.fetch(url,data)
link = HTML.fromstring(page).xpath("//a/@href")[0]
if not link.startswith('http://'): link = 'http://weibo.cn/%s' % link
# 手动跳转到微薄页面
self.fetch(link,"")
# 保存cookie
if cookie_filename is not None:
self.cj.save(filename=cookie_filename)
elif self.cj.filename is not None:
self.cj.save()
print 'login success!',data
def fetch(self, url,data):
print 'fetch url: ', url
req = urllib2.Request(url,data, headers=self.headers)
return urllib2.urlopen(req).read()
# 开始运行
fet=Fetcher();
fet.login("YOUR_SINAEMAIL","PASSWORD")
print fet.fetch('http://weibo.cn/ohmygossip', None)对网页文本的分析提取使用的是lxml,同样需要自己安装这个包。具体使用有官方文档不赘述。
Chrome Extension
扩展应用部分主要作用是制造假微博、监听被试的鼠标行为、接收传送数据和实验衔接。
制造假微博 (content_script.js)
接下来考虑用什么方式生成假微博。完全用代码生成一段html作为假微博是可以,但是会存在很多问题,比如被试一点击收藏、转发、评论、赞就会出错。我当然可以重写一段js专门用于假微博的收藏、转发等,但是对于基本没接触过js的人来说这样的学习成本太高,最终目的是为毕业设计服务,不能舍本逐末,因此只能作为备选。
最终选择了另一方法,注册个小号发一条和我想要做的假微博一模一样的微博,然后copy源代码,修改其中所有涉及userid的部分。比如下面这部分:
<div class="WB_face W_fl">
<div class="face">
<a target="_blank" class="W_face_radius" suda-uatrack="key=feed_headnick&value=pubuser_head:3842208606302871" href="/u/USERID?from=feed&loc=avatar" title="USERNAME"><img usercard="id=USERID" title="USERNAME" alt="" width="50" height="50" src="http://tp2.sinaimg.cn/USERID/50/5719659418/0" class="W_face_radius"></a>
</div>
</div>等到写插件的js时,就可以用字符串替代将所有的“USERID”和“USERNAME”替换为我想要的值。到这里,看上去似乎没什么问题,但是测试了几次,发现转发、赞和评论很成问题。譬如被试A给朋友A1的假微博点赞了,然后被试B看到了B1的假微博点了赞然后发现点赞名单里有被试A。还有点开评论列表,会有所有被试的评论。究其原因,所有的假微博都是以我小号的真实微博为蓝本修改的,所有的转发、评论、点赞都会集中到这条微博上。
考虑到会对所有按钮的点击进行监听,因此顺便加上了对转发、评论、点赞的处理,一旦出现多余的东西就删掉。
var elementClassList = new Array(
"pic",
"link",
"shoucang",
"pinglun",
"zhuanfa",
"zan",
"pingbiweibo",
"pingbiyonghu",
"quxiaoguanzhu",
"jubao",
"pingbiguanjianci"
);
// 添加事件监听
for (var i = 0; i < elementClassList.length; i++) {
var className = elementClassList[i];
var element = new_weibo.getElementsByClassName(className)[0];
element.onclick = function(){
var myDate = new Date();
if (this.className == "pinglun"){
var weibo = document.getElementsByClassName("cheatweibo")[0];
var list = weibo.getElementsByClassName("repeat_list");
if (list.length > 0)
list[0].remove();
}
if (this.className == "zhuanfa"){
var list = document.getElementsByClassName("repeat_list S_line1");
if (list.length > 0)
list[0].remove();
}
if (this.className == "zan"){
var like_status = this.getElementsByClassName("W_icon icon_praised_b");
if (like_status.length > 0){
var em = document.createElement("em");
em.innerHTML = " 1";
like_status[0].parentNode.appendChild(em);
like_status[0].setAttribute("class", "W_icon icon_praised_bc ");
}else{
like_status = this.getElementsByClassName("W_icon icon_praised_bc ");
while (like_status[0].parentNode.children[1])
like_status[0].parentNode.children[1].remove();
// like_status[0].parentNode.children[1].remove();
like_status[0].setAttribute("class", "W_icon icon_praised_b");
}
}
}//recordTime(className + "click");
if (className == "zan"){
element.getElementsByClassName("S_txt2")[0].setAttribute("action-type", "");
}
};所有的评论、转发都是实际发生的,评论做到这里就足够了,但是转发还存在问题,当被试转发后,转发的微博中的各项元素都暴露了真面目,这会导致被试发觉这是一条假微博。为此,写了一个每间隔10毫秒调用的函数,一旦发现目标就替换文本、值等。
// 实验中调用的函数
setInterval(
function(){
var list = new_weibo.getElementsByClassName("repeat_list");
if (list.length > 0){
list[0].remove();
var pinglun = new_weibo.getElementsByClassName("pinglunnum")[0];
pinglun.children[0].innerHTML = "评论";
}
var list = document.getElementsByClassName("repeat_list S_line1");
if (list.length > 0){
list[0].remove();
}
var zhuanfa = new_weibo.getElementsByClassName("zhuanfanum")[0];
zhuanfa.children[0].innerHTML = "转发";
var node = $("[title$='测试1号2015']")
if (node.length > 0){
node = node[0];
node.innerHTML = "@" + param.username;
node.href = "/u/" + param.userid +"?from=feed&loc=nickname";
node.setAttribute("nick-name", param.username);
node.setAttribute("usercard", "id=" + param.userid);
var str = '我在微商城购买了GlassRock。<span class="link"><a class="W_btn_b btn_22px W_btn_cardlink" title="iGlasses" href="http://simonproject.sinaapp.com/product.html" action-type="feed_list_url" alt="#"><i class="W_ficon ficon_cd_link S_ficon">O</i><i class="W_vline S_line1"></i><em class="W_autocut S_link1">点击了解:GlassRock</em></a></span>';
if (node.parentNode.parentNode.children[1])
node.parentNode.parentNode.children[1].innerHTML = str;
else
node.parentNode.parentNode.children[0].children[1].children[0].innerHTML = str;
// 图片
var pic = node.parentNode.parentNode.children[2];
if (pic)
pic.getElementsByClassName("bigcursor")[1].src = "http://simonproject.sinaapp.com/glasses.jpg";
// 时间戳
if (node.parentNode.className != "getTogether-txt")
var t = node.parentNode.parentNode.children[4].children[1].children[0];
if (time && t)
t.setAttribute("date", time);
node.title = param.username;
}
},
10
);
// 非实验中时调用函数
setInterval(
function(){
if (data.isstart == false){
var nodes = $("[title$='测试1号2015']");
for (var i = 0; i < nodes.length; i++){
nodes[i].parentNode.parentNode.parentNode.parentNode.parentNode.parentNode.remove();
}
}
},
10);然而这一项伪造工作还没有完。被试总共要进行5次test,如果每次实验开始后第一条都是这条微博未免太可疑,但是随机插入微博列表肯定会影响被试对这条微博的注意,比如被试在浏览前几条时肯定还比较耐心,越往后越心不在焉。我们需要被试注意到这条微博,但是又不能显得太刻意,于是决定放在第三条。那么,新的问题又有了,微博时间戳必须是在前后两条微博之间。
// 替换时间戳
var timenode = new_weibo.getElementsByClassName('S_txt2')[1];
var cankao_timenode = weibo.getElementsByClassName("WB_from S_txt2")[0].children[0];
for (var x=0;x < cankao_timenode.attributes.length;x ++){
if (cankao_timenode.attributes[x].localName == "date"){
var time = Number(cankao_timenode.attributes[x].value) + 1000;
break;
}
}
timenode.setAttribute("date", time);
timenode.innerHTML = cankao_timenode.innerHTML;
// 插入到微博列表中
weibo = document.getElementsByClassName('WB_cardwrap WB_feed_type S_bg2')[2];
weibolist.insertBefore(new_weibo, weibo);至此,伪装的工作算是完成了。然后再用自己简陋的html、css认知加上了也购买了该产品的微博用户列表,直接用点赞的用户列表修改加上。
监听被试的鼠标行为 (content_script.js)
相对伪装,监听就简单多了。
var data = {
isstart : false,
subjectID : null,
username: null,//"大自然保护协会-马云",
userid: null,//2145291155,
linkclick:null,
picclick:null,
shoucangclick:null,
zhuanfaclick:null,
pinglunclick:null,
zanclick:null,
pingbiweiboclick:null,
pingbiyonghuclick:null,
quxiaoguanzhuclick:null,
jubaoclick:null,
pingbiguanjianciclick:null,
weibomouseover:null,
weibomouseout:null,
totaltime:0,
date:null,
url : window.location.href,
};
var elementClassList = new Array(
"pic",
"link",
"shoucang",
"pinglun",
"zhuanfa",
"zan",
"pingbiweibo",
"pingbiyonghu",
"quxiaoguanzhu",
"jubao",
"pingbiguanjianci"
);
// 添加事件监听
for (var i = 0; i < elementClassList.length; i++) {
var className = elementClassList[i];
var element = new_weibo.getElementsByClassName(className)[0];
element.onclick = function(){
var myDate = new Date();
//记录发生该点击时的时间
data[this.className+"click"] = myDate.getTime();
}
//统计鼠标在该微博上的停留时间
new_weibo.onmouseenter = function(){
var myDate = new Date();
data.weibomouseover = myDate.getTime();
};
new_weibo.onmouseleave = function(){
var myDate = new Date();
data.weibomouseout = myDate.getTime();
if (data.weibomouseout > data.weibomouseover)
data.totaltime += data.weibomouseout - data.weibomouseover;
};数据传输 & UI
现在,我们有了伪造的微博,有了监听的数据,可是被试是用自己的电脑进行实验,我该如何在不在场的情况下让被试得到博主信息、生成假微博、完成实验上传数据呢? 于是我们需要一个服务器存放被试和博主的对应关系、博主的信息、被试的实验数据,一个或一些web界面让被试知道当前他需要做什么、提醒他做实验、结束实验、反馈bug、上传数据等。服务器先不管,先将被试本地的插件部分做好。
首先,我们来了解下chrome的结构才能开始进行数据传输。下图来自博文《Chrome插件(Extensions)开发攻略》
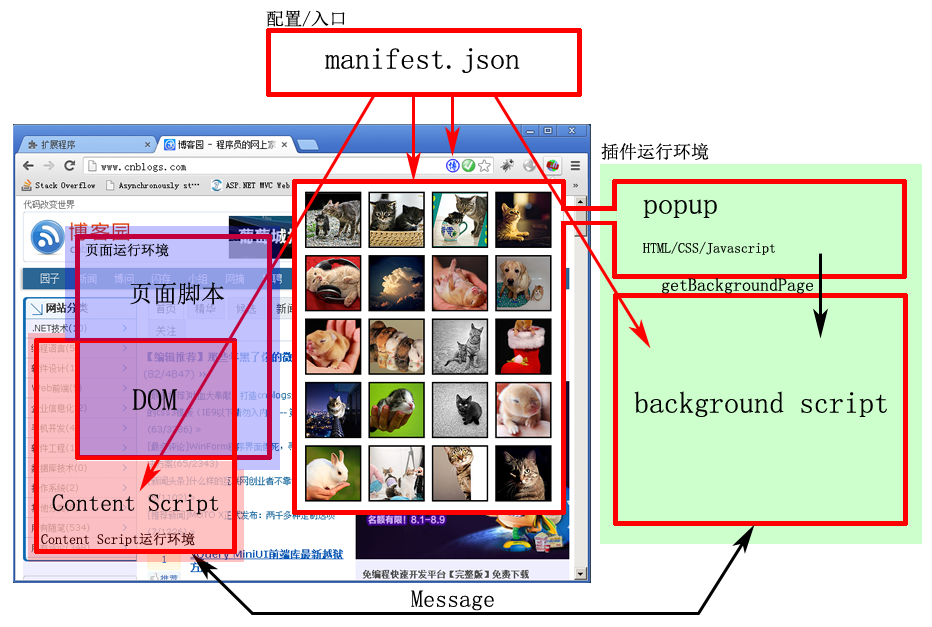
伪造微博的是content_script.js,而存储本地数据的则是background.js,因此顺序是这样的: background.js–(被试数据)–>服务器–(被试关注的博主数据)–>background.js–(被试关注的博主数据)–>content_script.js–(监听数据)–>background.js–(监听数据)–>服务器
background和content_script之间通过sendMessage/onMessage函数传递数据,而background则通过jquery的ajax接收发送服务器数据。
搞清楚了基本的东西,照猫画虎即可。
// content_script向background发送message
chrome.runtime.sendMessage(value,function(response){
callback(response);
});
// background中监听从content_script发来的message
chrome.runtime.onMessage.addListener(
function(request, sender, sendResponse) {
console.log(sender.tab ?
"from a content script:" + sender.tab.url :
"from the extension");
});
// 向服务器发送request
$.ajax({
url: "http://simonproject.sinaapp.com/test.php",
// cache: false,
type: "POST",
data: data,//JSON.stringify({url:data.url, isstart:data.isstart,totaltime:data.totaltime}),
dataType: "json",
timeout: 1000,
async: false,
success:function(data, textStatus){
console.log(textStatus + ":" + JSON.stringify(data));
if (data.result == true){
var user = JSON.parse(localStorage[userid]);
user.done = "true";
localStorage[userid] = JSON.stringify(user);
}
},
error:function(XMLHttpRequest, textStatus, errorThrown){
console.log("error" + textStatus + errorThrown);
},
complete:function(XMLHttpRequest, textStatus) {
console.log("complete:"+textStatus);
}
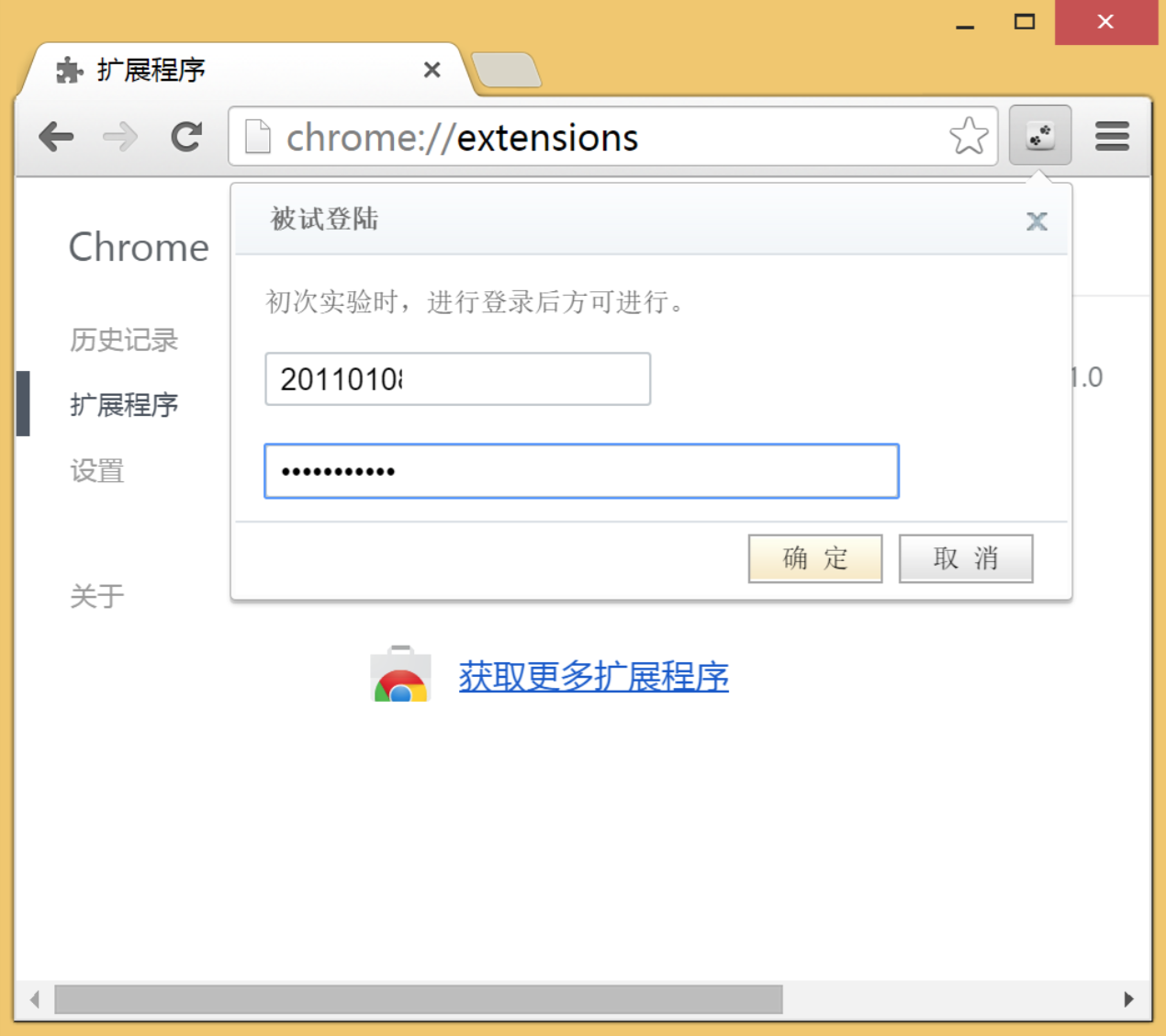
});核心的东西完成后,剩下就是修缮实验的体验,因为不懂css,直接拿了网易邮箱的登录插件修改,被试需要先登录,然后进入实验信息界面。
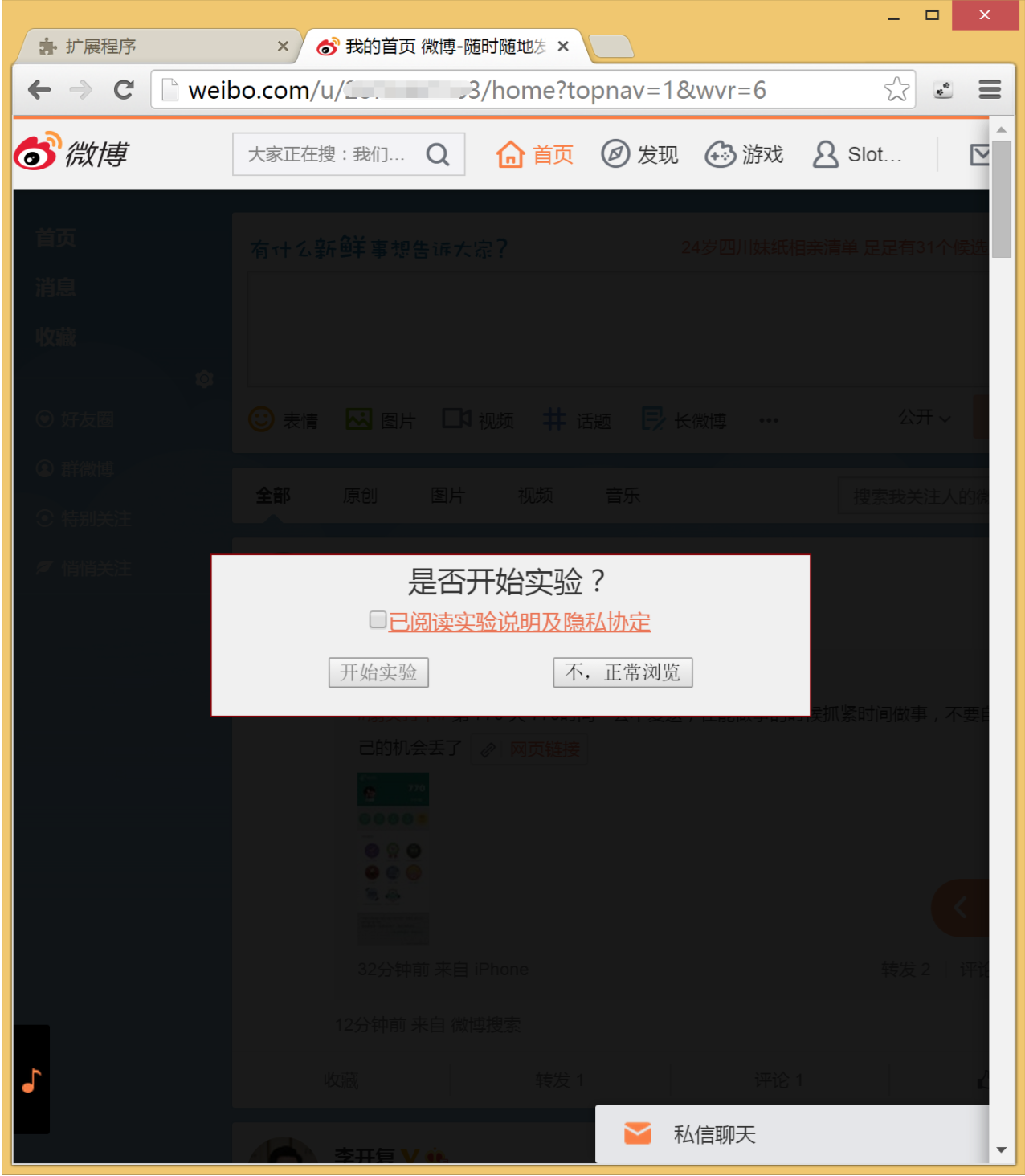
 之后每一次打开微博都会出现下述界面:
之后每一次打开微博都会出现下述界面:
 如果网页没有加载完,就会发出提示(主要是为了避免网页加载不完全而无法显示出假微博):
如果网页没有加载完,就会发出提示(主要是为了避免网页加载不完全而无法显示出假微博):
 结束实验(关闭或刷新页面时)弹出提示:
结束实验(关闭或刷新页面时)弹出提示:
 每次实验后理应会自动上传数据,但倘若断网或其他原因没有成功上传,也会有所提示:
每次实验后理应会自动上传数据,但倘若断网或其他原因没有成功上传,也会有所提示:
 全部5次实验完成后,会提示被试填写实验后问卷:
全部5次实验完成后,会提示被试填写实验后问卷:

Server
服务器端主要是php,被试登录时验证一下,收到实验数据时写入数据库,不得不说SAE的MySQL不好用,官方因为安全问题也不提供接口供navicat管理。好在我的数据也不复杂、不多。
除此之外,还有反馈功能,当实验出现问题时可以反馈到我的邮箱。当实验开始后一夜,邮箱就飞来了很多邮件,即使提供了在线FAQ供被试查阅,还会有意料之外的情况。很快就改了插件的bug放到服务器上供下载。
猜测游戏或者APP上线的头几天,程序猿们都是忙的焦头烂额的吧……
最后,假商品网页,网上的品玩网站模版修改成。本来想把网页地址也伪装,但是查了资料后发现chrome为了防止恶意的行为,禁止对地址栏进行修改,如果只是改后缀还可以,但是改域名是不可能的。也没有找到隐藏地址栏的方法。
实验结论
用minitab对数据检验后证明了猜想。
首先,对于个人来说,朋友的推荐效果好于网红的推荐,很多人一看到朋友买的就一言不合点击了商品链接,甚至还有点购买的……但也并不是说网红的推荐没有效果,可以这么说,前者是会心一击,后者是温水煮青蛙。病毒式营销。
除此之外,很多人以为自己很反感网红做广告,实际在实验中和实验后发觉并没有那么反感,调研的结果是因为没有预期那么浓重的推销意味,同时又是喜欢的博主,反而有了兴趣。找网红做广告,加点段子加点干货,绝对是康庄大道。
最后一点,很多人在实验前对智能眼镜兴致勃勃(涉入度高),实验后反而兴致缺缺(涉入度低),究其原因是因为商品界面的智能眼镜低于期待值。拿自己的体验一想也很能理解了,从没见过海的所以对碧海蓝天很期待,结果到了青岛一看黄浊的海便再难对海提起兴趣了。如果一款APP一开始的体验就太差,后面得付出更多更多的努力才能把用户拉回来吧。
不足
- 写插件是写到哪想到哪,于是代码写的很没水准,如果我是产品经理的话已经被程序猿分分钟砍死吧……还是要做好规划,小东西想到哪写到哪就算了,大项目就不能乱来了。
- 正如答辩时赵晓波老师所言,我并没有一个清晰的研究目标=.=,就是觉得好玩就研究了……不够严谨,太粗糙
- 其实要是不搞四个分组,说不定还可以做做聚类,或者弄个persona看看都是些什么组成。
- 少数聪明的被试从每次出现的微博内容都一样推测出这是实验的一部分,如果假微博是转发的微博的话,那么多人转发相同的内容也可以理解,可以降低被发现的概率
- 实验中,没有禁止被试和其他人沟通微博的内容,于是两个同一宿舍的妹子一起参加了实验,另一妹子就奇怪问舍友“你什么时候买了VR了”,然后实验就暴露了……