简介
2013-2014年参与的校内SRT项目,抓取11个热门城市未来90天起飞的机票价格,以此来建模预测飞机票价格的变化。
- Python写就爬虫、网页解析、图形化界面、决策树训练、预测。
- MySQL存储数据
- 决策树作为预测模型
- 结论:飞机票的价格变化确实有pattern,不同时间段起飞、不同日期起飞等都会造成影响。 |Github项目传送门|
技术实现
爬虫
- 语言:Python2.7
- 抓取对象:www.ceair.com 东方航空官方网站
当时刚刚自学了Python,本想用Google开发的Scrapy框架,但是发现对于网页的获取加载等等原理都不明白,还不如自己从头学起写一个爬虫。因此使用的都是Python2.7自带的库,如utllib等。
Request
模拟浏览器Get和Post的过程使用的是Chrome浏览器自带的“检查”功能,其中的“Network”部分可以查看所有的Get和Post,包括参数、Headers、Cookies等等。 代码重写或者更改过很多次,最后的读取网页部分变成了这样:
# 城市中文名
deptcdtxt = dept
arrcdtxt = arr
# 获取城市代码
dept = city.get_cd(dept)
arr = city.get_cd(arr)
# 获取机场代码
deptcitycode = city.get_citycode(deptcdtxt)
arrcitycode = city.get_citycode(arrcdtxt)
# Post参数(出发城市,到达城市)&Headers
url = 'http://easternmiles.ceair.com/booking/flight-search!doFlightSearch.shtml?rand=0.4091873385477811'
values = {'searchCond':'{"segmentList":[{"deptCdTxt":"DEPT-TXT","deptCd":"DEPT","deptNation":"CN","deptRegion":"CN","deptCityCode":"DEPT-CITYCODE","arrCd":"ARR","arrCdTxt":"ARR-TXT","arrNation":"CN","arrRegion":"CN","arrCityCode":"ARR-CITYCODE","deptDt":"DATE"}],"tripType":"OW","adtCount":"1","chdCount":"0","infCount":"0","currency":"CNY","sortType":"t"}'}
values['searchCond'] = values['searchCond'].replace('DEPT-TXT', deptcdtxt)
values['searchCond'] = values['searchCond'].replace('ARR-TXT', arrcdtxt)
values['searchCond'] = values['searchCond'].replace('DEPT-CITYCODE', deptcitycode)
values['searchCond'] = values['searchCond'].replace('ARR-CITYCODE', arrcitycode)
values['searchCond'] = values['searchCond'].replace('DEPT', dept+'#')
values['searchCond'] = values['searchCond'].replace('ARR', arr+'#')
referer = 'http://easternmiles.ceair.com/flight/'+dept+'-'+arr+'-DATE_CNY.html'
save = {}
save['searchCond']=values['searchCond']
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.114 Safari/537.36',
'X-Requested-With':'XMLHttpRequest',
'host':'easternmiles.ceair.com',
'Connection':'keep-alive',
'Origin':'http://easternmiles.ceair.com'}
import cookielib
cookie = cookielib.CookieJar()
ck = urllib2.HTTPCookieProcessor(cookie)
# 代理
proxy_id = random.randint(0, len(proxy)-1)
proxies = {'http': proxy[proxy_id]}
handler = urllib2.ProxyHandler(proxies)
opener = urllib2.build_opener(handler, ck, urllib2.HTTPHandler)
# 修改起飞日期
date = time.strftime('%Y-%m-%d',time.localtime(time.time()+sta*24*60*60+i*24*60*60))
date2 = time.strftime('%Y%m%d',time.localtime(time.time()+sta*24*60*60+i*24*60*60))
values['searchCond'] = save['searchCond']
values['searchCond'] = values['searchCond'].replace('DATE',str(date))
headers['Referer'] = referer.replace('DATE', str(date2)[2:])
# 读取网页
data = urllib.urlencode(values)
req = urllib2.Request(url, data, headers=headers)
time.sleep(5)
response = opener.open(req)设置Headers、Cookie处理、代理和sleep都是为了防止被反爬虫机制给检测出来,但是依然会时不时被屏蔽,非常影响抓取的连续性和稳定性,因此又试着加上了容错提高鲁棒性。
err = 0
while err < 2 and err >= 0:
try:
#对values进行url编码
data = urllib.urlencode(values)
#建立一个request类型的对象
req = urllib2.Request(url, data, headers=headers)
time.sleep(5)
#response为post后返回的内容
response = opener.open(req)
#获取response成功后将err标志改为-1
err = -1
except urllib2.HTTPError,e:
print 'HTTPError:',e.code
#writeErr(e.read(),'HTTPError:'+e.code,date,dept,arr)
err = err + 1
continue
except urllib2.URLError,e:
print 'URLError,please check the net.\n'
print e.reason
err = err + 1
continue
except err:
print err
print "Error, it is possible that the computer doesn't connect to the Internet.\n"
writeErr('无','打开网页失败',date,dept,arr)
err = err + 1
continue
#如果是因为两次尝试都失败而跳出循环则跳过这个起飞日期的爬取
if err >= 2:
continue
#读取为string类型
temp = response.read()
response.close()
opener.close()
#去掉影响json解析的字符
temp = temp[temp.find('{'):]
try:
#对json格式的数据进行解析
text = json.loads(temp)
except:
print 'json解析失败!'.decode('utf-8')
writeErr(temp,'json解析失败',date,dept,arr)
continue
try:
#剔除没有航班的航线
#print values
#print temp
if text['adtNum']!=0:
#提取所需信息
for a in range(len(text['tripItemList'][0]['airRoutingList'])):
#某一航班
site = text['tripItemList'][0]['airRoutingList'][a]
#预加入出发与到达城市
flight=[dept,arr]
if site['priceDisp']['lowest']:
#选择有票价的航班抓取
#航班号
flight.append(site['flightList'][0]['flightNo'])
#机型
flight.append(site['flightList'][0]['acfamily'])
#出发日期
flight.append(site['flightList'][0]['deptTime'][0:10])
#出发时间
flight.append(site['flightList'][0]['deptTime'][11:])
#最低价格
flight.append(site['priceDisp']['lowest'])
#抓取日期
flight.append(time.strftime('%Y-%m-%d',time.localtime(time.time())))
flight = tuple(flight)
flights.append(flight)
else:
continue
else:
print '没能抓取%s从%s至%s的机票信息\n'%(date, dept, arr)
continue
except:
print '提取信息失败!'
writeErr(temp,'提取信息失败',date,dept,arr)
continue爬虫的主体部分算完成了。
代理
防止被屏蔽重要的一点是代理,代理也可以从网上的免费代理网站爬取存到文件中,在爬虫运行时,读取到内存中随时取用。
def getproxy():
""" 获取代理 """
f = open('proxy.txt','r')
text = f.read()
f.close()
p = text.split('\n')
p = p[:-1]
return p
proxy = getproxy()抓代理用的爬虫是从网上找的现成轮子,免得自己造了。因为不是自己的代码,不在此列出,但在github里面还是找得到的。
与数据库的对接
数据库用的是MySQL,因此需要下个MySQLdb的Python库来进行数据库操作。这方面没什么花头,按文档写即可。
import time
import MySQLdb
def opendb(db_name):
conn = MySQLdb.connect(host='localhost', user='root',passwd='root',db=db_name,charset="utf8")
cursor = conn.cursor()
cursor.execute('set interactive_timeout=24*3600')
return (conn,cursor)
def closedb(conn, cursor):
cursor.close()
conn.close()
def insertTomysql(flights):
"""
用以插入mysql数据库
flights = [(出发城市,到达城市,航班号,机型,出发日期,出发时间,价格,抓取日期)*n]
"""
conn = MySQLdb.connect(host='localhost', user='root',passwd='root',db='ceair',charset="utf8")
cursor = conn.cursor()
try:
for flight in flights:
try:
cursor.execute('insert ignore into city (flight,deptcity,arrcity) values (%s, %s, %s)',[flight[2],flight[0],flight[1]])
cursor.execute('insert ignore into departure (flight, type, deptDate, deptTime) values (%s, %s, %s, %s)',flight[2:6])
cursor.execute('select id from departure where flight = %s and deptdate = %s',[flight[2],flight[4]])
id = cursor.fetchone()[0]
cursor.execute('insert ignore into `fetch` (price,fetchdate,deptID) values (%s, %s, %s)',[flight[6],flight[7],id])
except:
print '没有成功写入:'.decode('utf-8'),flight
db_err(flight)
conn.commit()
print '成功写入数据库。'.decode('utf-8')
except MySQLdb.Error,e:
#错误回滚
conn.rollback
for flight in flights:
db_err(flight)
print "Error %d: %s" % (e.args[0],e.args[1])
cursor.close()
conn.close()
def db_err(err_record):
today = time.strftime('%Y-%m-%d',time.localtime(time.time()))
fout = open('db_err_'+today+'.txt','a')
for i in err_record:
fout.write(str(i)+' ')
fout.write('\n')
fout.close()多线程
考虑到要抓取11个城市之间的航班,也就是110个航线,1500+的航班,采用多线程是势在必行的。
class ceair_thread(threading.Thread):
def __init__(self,dept,arr,sta=0,ran=1):
threading.Thread.__init__(self)
self.dept = dept
self.arr = arr
self.sta = sta
self.ran = ran
def run(self):
start = clock()
flights = ceair_spider(self.dept,self.arr,self.sta,self.ran)
print '线程%s-->%s用时%s\n' %(self.dept, self.arr, clock()-start)先建立线程类,然后创建调用多个线程:
from ceair_spider import *
from time import clock
from time import sleep
import time
from insertToDB import *
while 1:
clock()
fout = open('ceair_log2.txt','a')
today = time.strftime('%Y-%m-%d %H %M %S',time.localtime(time.time()))
fout.write('%s the spider has been started.\n' % today)
#hot_city = ['上海','北京']
hot_city=['上海','北京','昆明','西安','广州','成都','杭州','青岛','深圳','太原','长沙']
threads = []
#打开数据库
#conn, cursor = opendb('ceair')
for i in range(0,len(hot_city)):
for j in range(0, len(hot_city)):
if i!=j:
new_thread = ceair_thread(hot_city[i],hot_city[j], 0, 20)#conn,cursor,0,90)
threads.append(new_thread)
# new_thread = ceair_thread(hot_city[0],hot_city[1], 0, 10)#conn,cursor,0,90)
# threads.append(new_thread)
for athread in threads:
athread.start()
for athread in threads:
athread.join()
used_time = clock()
print '总用时', used_time
#关闭数据库
#closedb(conn, cursor)
fout.write('Finished. Time used:%s\n' % used_time)
fout.close()
if used_time <= 86400:
sleep(86400-used_time)数据库
对于新手,老老实实先从关系型数据库学起,专业课上学的不是极复杂的Oracle就是极鸡肋的Access,都不合适实际个人研究用。而MySQL是免费又稳定更新的关系型数据库软件,还有大量文档,用来练手再合适不过。
理论上要按学的三大范式来设计,不过实际涉及到效率就不可能严格要求了,好在我们要存的数据并不复杂,E-R图如下:
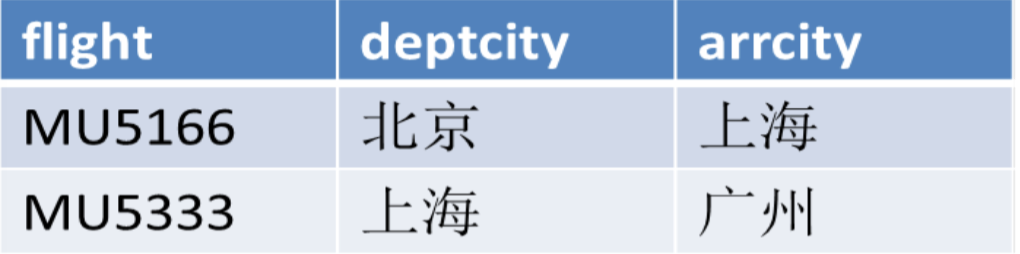
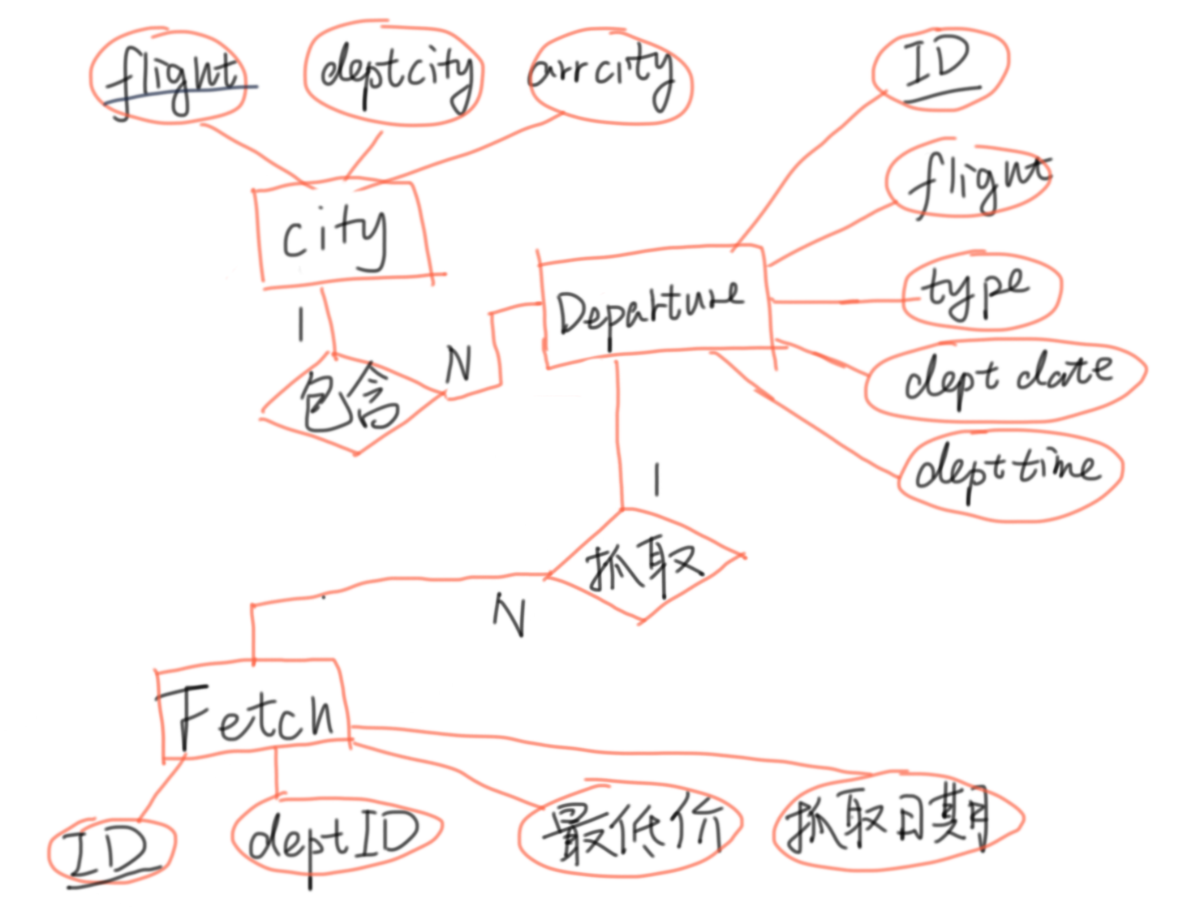 city存储航线信息,departure存储航班信息,fetch存储价格信息,具体的存储格式如下:
city:
city存储航线信息,departure存储航班信息,fetch存储价格信息,具体的存储格式如下:
city:
 departure:
departure:
 fetch:
fetch:
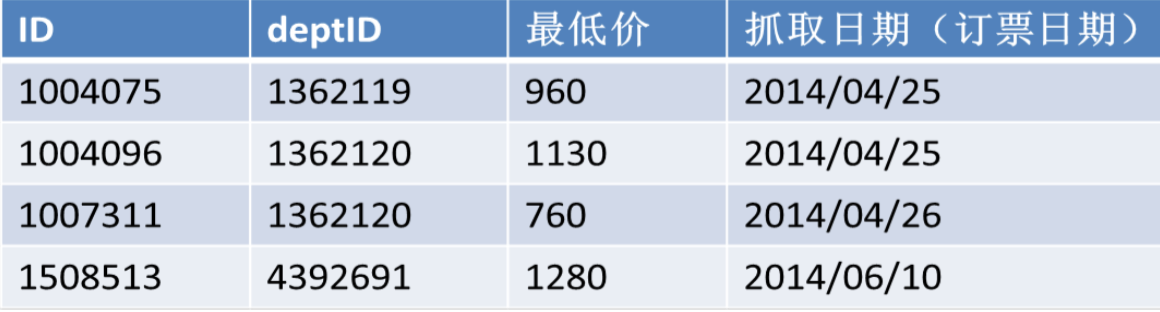
数据
Summary
- 来源:东方航空官方网站
- 抓取时间跨度:2013/12~2014/5/25,每一天抓取未来90天起飞的航班价格
- 城市范围:北京、上海、昆明、西安、广州、成都、杭州、青岛、深圳、太原、长沙
- 数据规模:1556个航班,237504个出发信息,总数据量7739641条
预处理
- 空缺值:由于数据是从网络上爬取,有时会有数据缺失。比如由于某一天没有爬取而导致对应这一天购买所有的航班数据都缺失了。 处理方法:以合理的方式填充这些数据。用后一天爬取的数据填补空缺的数据。如果连续5天的数据都缺失,我们只能考虑将所有含缺失的相关数据全部删掉不用。
- 噪声:在我们爬取到的数据中,可能会存在一些异常的噪声点。比如有时当经济舱机票售完后,我们爬到的就会是头等舱的机票价格,要显著高于普通机票价格。如果直接用来做分析,显然会得到错误的规律与结论。 处理方法:以标准经济舱价格替换这些数据。
- 不一致:在我们的数据中,没有明显的不一致现象。
- 集成:我们收集到的数据的各项属性中显然有一些是相关的,比如提前预定的天数就可以由预定日期与出发日期得到,而除了一些特殊情况,飞机的机型基本上可以由航班号确定。 处理方法:对数据进行相关性分析,将相关性高的数据项进行集成,以减少数据的维度。
- 概化:在我们收集到的数据中,或有一些过于详细的信息。比如飞机的起飞时间是精确到秒的。事实上,我们显然不需要这么精确的数据,因为这样不仅工作量会变大且更复杂,还可能会得不到正确的结论。因此我们需要对数据进行概化。 处理方法:按起飞时间是否为深夜清晨,将起飞事件处理为0,1变量。
可视化
为了方便查看数据变化,利用Python的两个开源库wx和matplotlib来做了UI。
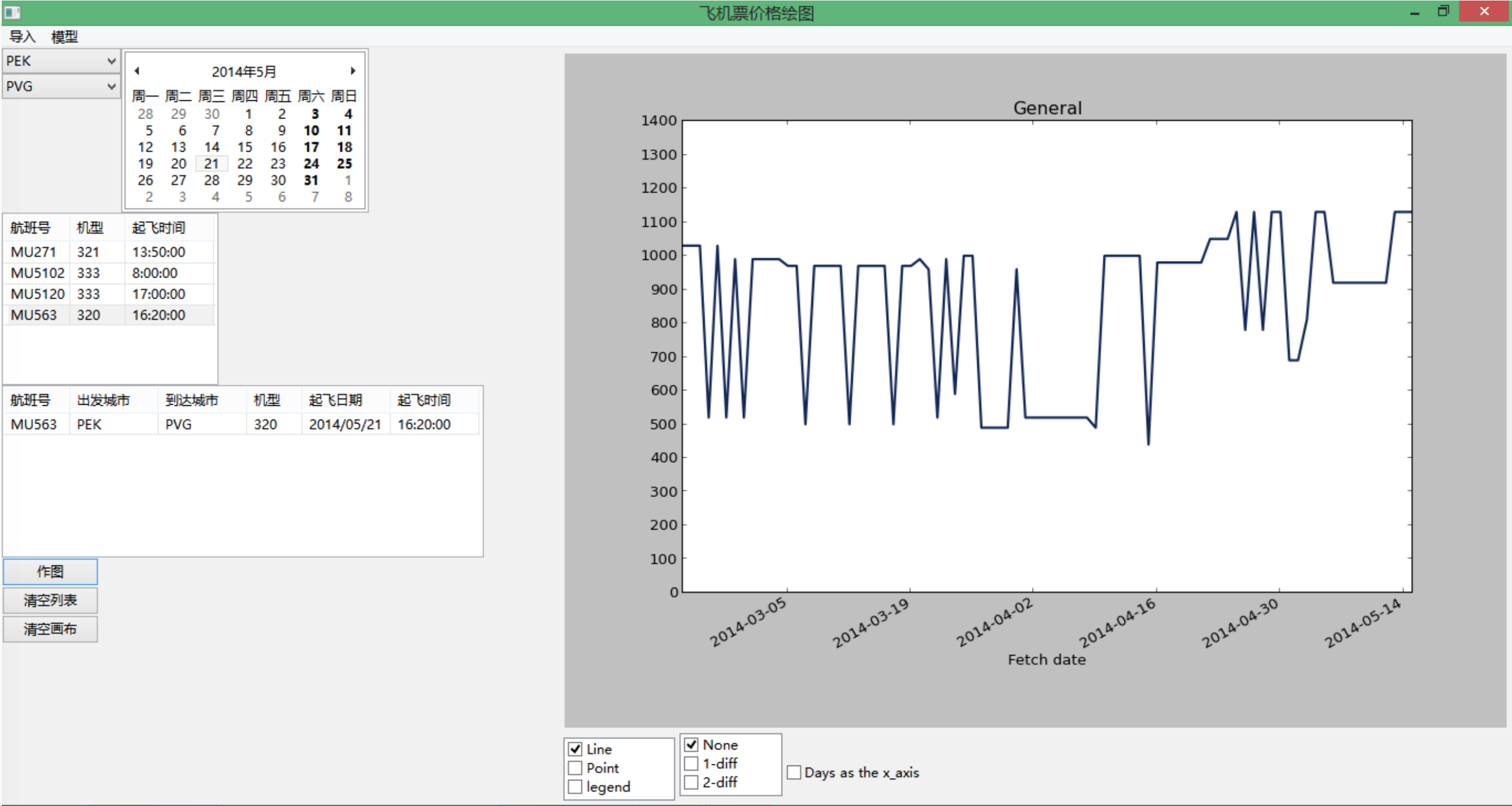 可以根据选择,在图上画出多条价格曲线,鼠标移动时可以高亮相应的曲线并在下方显示为几月几日出发的航班。可作图类型有无差分价格曲线、一阶差分价格曲线和二阶差分价格曲线,本来想要尝试3D显示,但是并不理想而且效率较低,故而放弃了这个功能。
横坐标的显示默认为订票日期,也可以选择为距离起飞的天数。
可以根据选择,在图上画出多条价格曲线,鼠标移动时可以高亮相应的曲线并在下方显示为几月几日出发的航班。可作图类型有无差分价格曲线、一阶差分价格曲线和二阶差分价格曲线,本来想要尝试3D显示,但是并不理想而且效率较低,故而放弃了这个功能。
横坐标的显示默认为订票日期,也可以选择为距离起飞的天数。
Pattern
利用这个作图程序,我们观察了MU5120(北京至上海)五月起飞的所有航班:
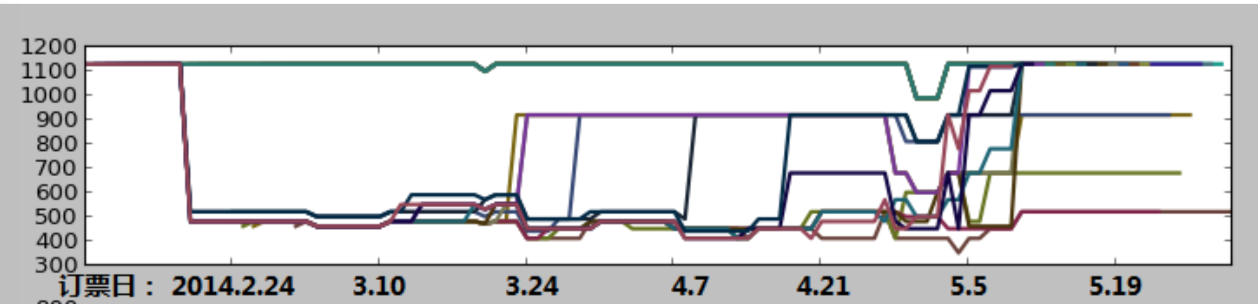 可以大体猜想分为三类:
可以大体猜想分为三类:
- 最上一簇,价格基本保持不变
- 中间一簇,早期低价,中期上升到800~900元
- 最下一族,基本处于低价,在最后几天升高
为了确认猜想,进一步分日期绘图,得到以下曲线:
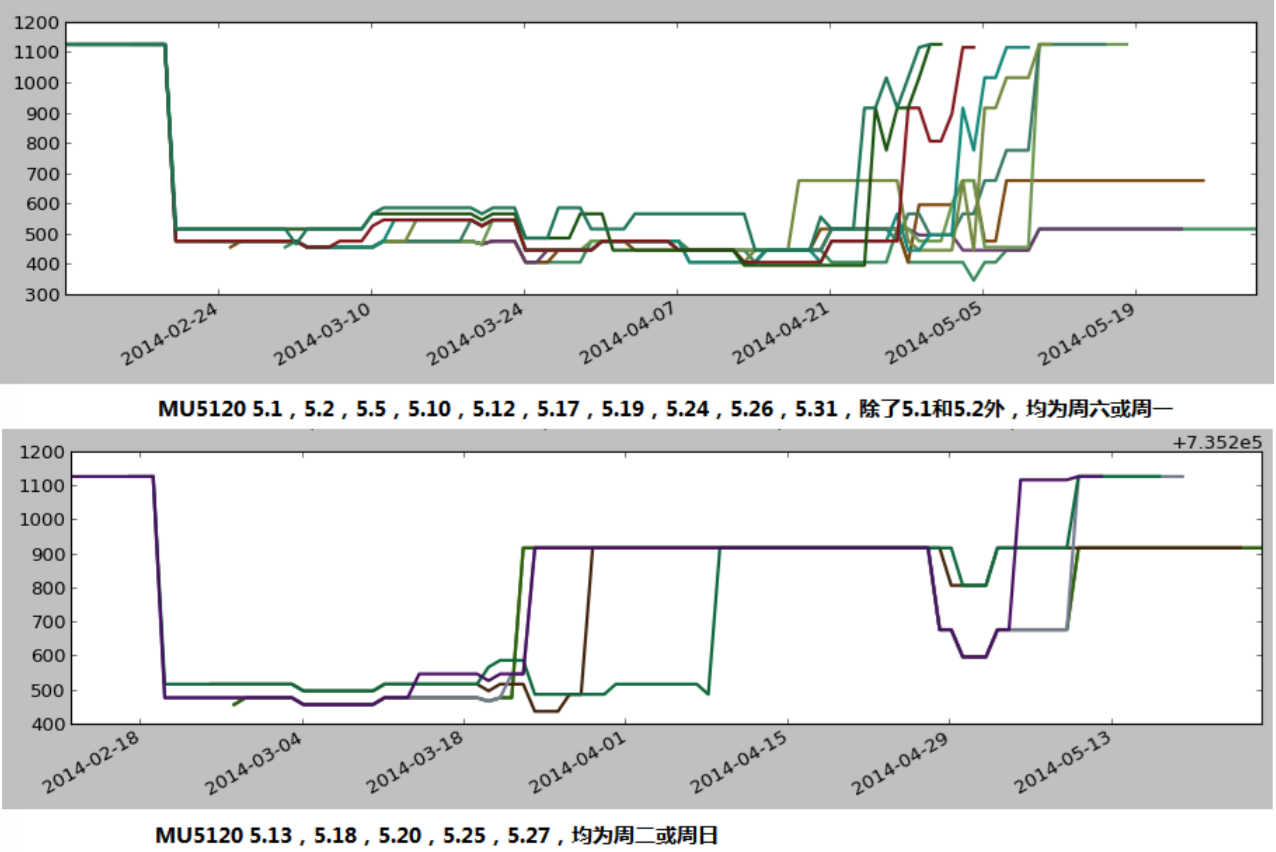 可以看出,基本保持低价的航班基本都是周六或周一起飞,5月1日与5月2日虽然不是周六或周一,但考虑其为劳动节放假,所以与周六或周一具有相同的模式。 而中期增高的航班均为周二或周日。
可以看出,基本保持低价的航班基本都是周六或周一起飞,5月1日与5月2日虽然不是周六或周一,但考虑其为劳动节放假,所以与周六或周一具有相同的模式。 而中期增高的航班均为周二或周日。
而观察MU5120周三至周五的所有航班,发现也具有同样的模式,且为我们之前猜想的第一类曲线。
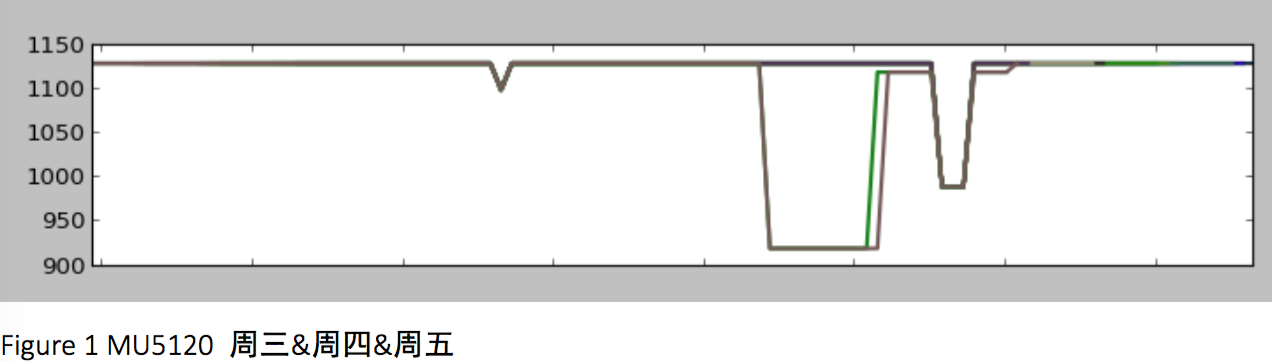 由此可见,周几对于航班价格的变化确实有影响。 接下来一步思考的便是,是否其他的航班也有类似的规律呢?
于是就针对Figure 1中的曲线类型,寻找类似的航班。
由此可见,周几对于航班价格的变化确实有影响。 接下来一步思考的便是,是否其他的航班也有类似的规律呢?
于是就针对Figure 1中的曲线类型,寻找类似的航班。
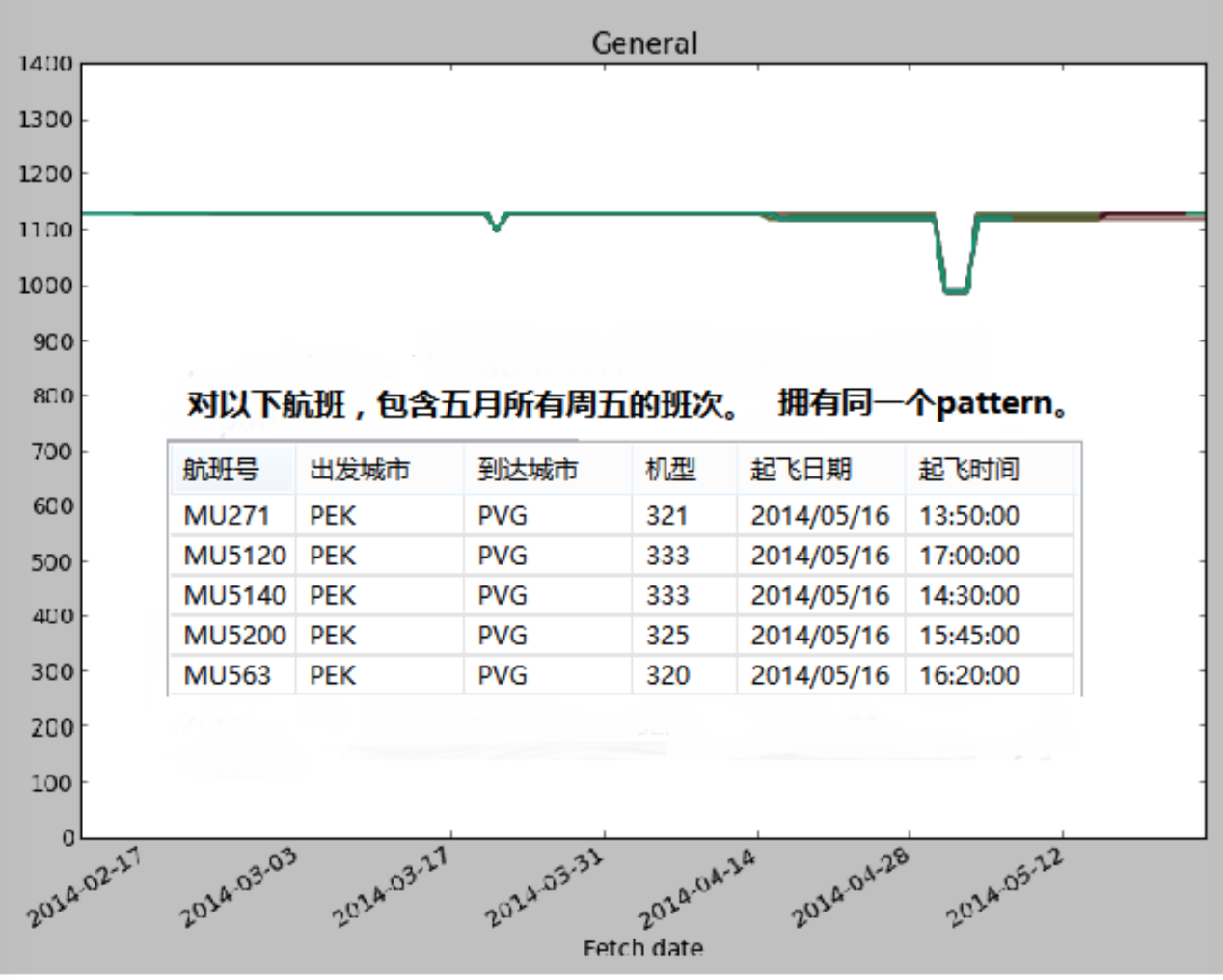 发现对于北京到上海的航班,如果不是深夜或者早晨出发,基本上所有周五起飞的航班都具有这样的模式。不知道是否可以认为,北京到上海周五的航班舱位一向紧缺,所以价格基本是维持原价。
而在这个探索的过程中,也可以认为航班起飞的时间点也是影响价格变化曲线的一个重要因素。
发现对于北京到上海的航班,如果不是深夜或者早晨出发,基本上所有周五起飞的航班都具有这样的模式。不知道是否可以认为,北京到上海周五的航班舱位一向紧缺,所以价格基本是维持原价。
而在这个探索的过程中,也可以认为航班起飞的时间点也是影响价格变化曲线的一个重要因素。
决策树
特征集
所谓决策树,最简单的理解就是很多个嵌套的if-else语句,其形象化的表示如下:
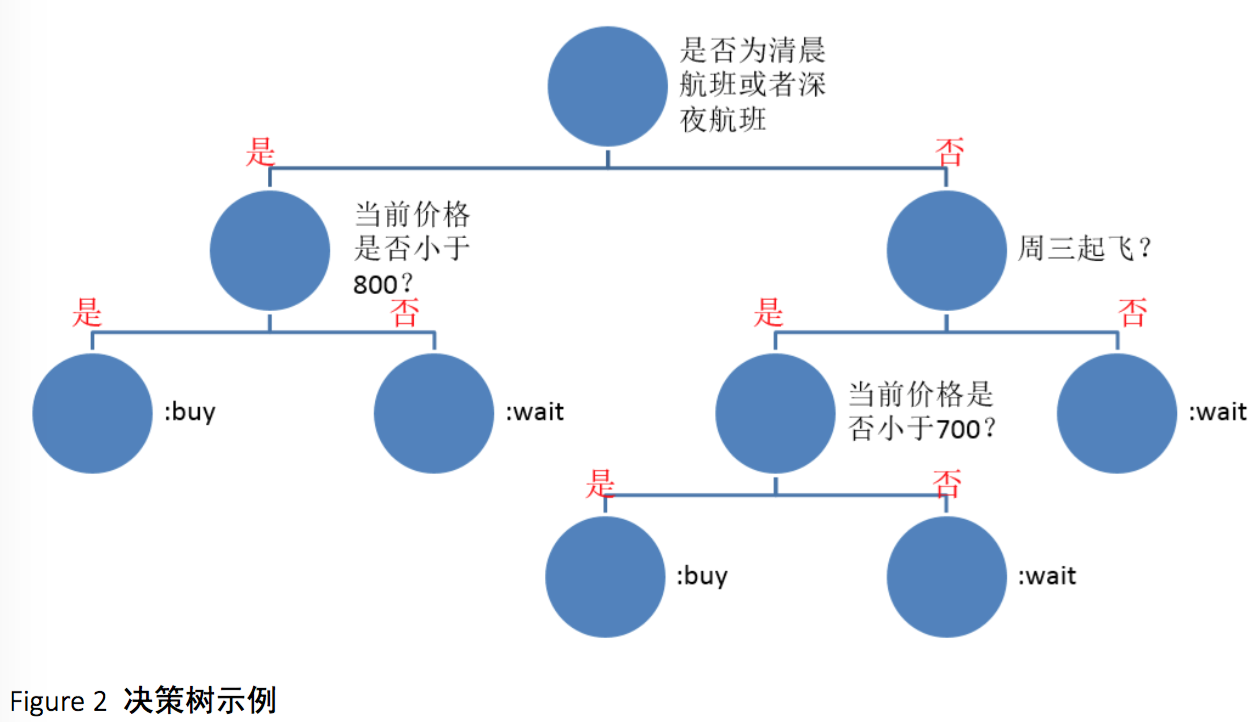 决策树在每个结点都有一个判断条件,然后根据判断的结果走向不同的分支,最后到达叶子结点,根据叶子结点存储的结果来给出预测结果。判断条件越早出现,其重要性便越高。所以决策树非常便于我们理解各个因素的意义和重要性。
决策树在每个结点都有一个判断条件,然后根据判断的结果走向不同的分支,最后到达叶子结点,根据叶子结点存储的结果来给出预测结果。判断条件越早出现,其重要性便越高。所以决策树非常便于我们理解各个因素的意义和重要性。
Figure 2展示了我们的决策树可能的样子,当然实际的决策树远远要庞大许多,而非示例的 这么简洁。
选择每个结点分类的标准可以分为两类,一类是信息熵,另一类是基尼不纯度。 香农定义的一个事件的信息量为:$I(X)=log_2(\frac{1}{p(x)})$,而如果X有n个随机事件,那么信息熵便是这n个事件的概率关于信息量的加权平均。熵越大,集合或者系统越混乱。
而基尼不纯度则是一个随机事件变成它的对立事件的概率,譬如一个随机事件Y,$P(Y=0)=0.1$,$P(Y=1)=0.9$,那么基尼不纯度就为$P(Y=0)(1-P(Y=0))+P(Y=1)(1-P(Y=1))=0.18$ 。不纯度越高,集合或系统越混乱。
而我们的结点的选择是要使分类后的子集混乱程度降低,变得有序。在我们的决策树中选择了基尼不纯度作为分类标准。
而根据前面做的准备工作,我们设定特征集为:
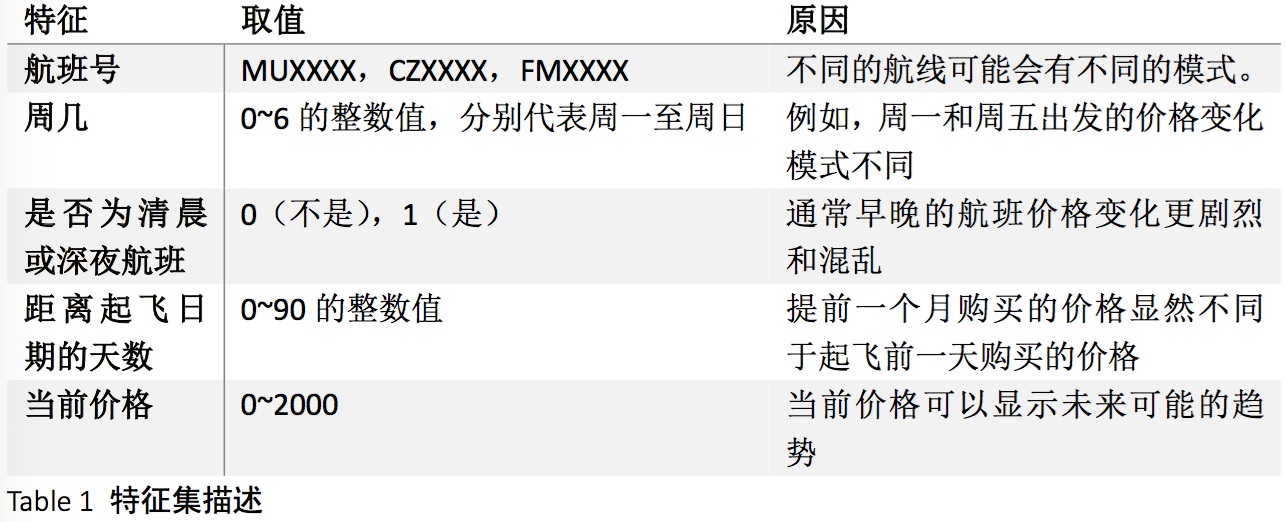 决策变量则是“buy”和“wait”。
决策变量则是“buy”和“wait”。
预测效果
鉴于过大的数据量可能会运行较长的时间,我们先对一个航班尝试了训练测试,选择的训 集和测试集在订票日期上相互独立。
 可以看出正确率相当高,但这个正确率是否是偶然还是稳定的还未可知。我们进行了下一步的测试。
可以看出正确率相当高,但这个正确率是否是偶然还是稳定的还未可知。我们进行了下一步的测试。
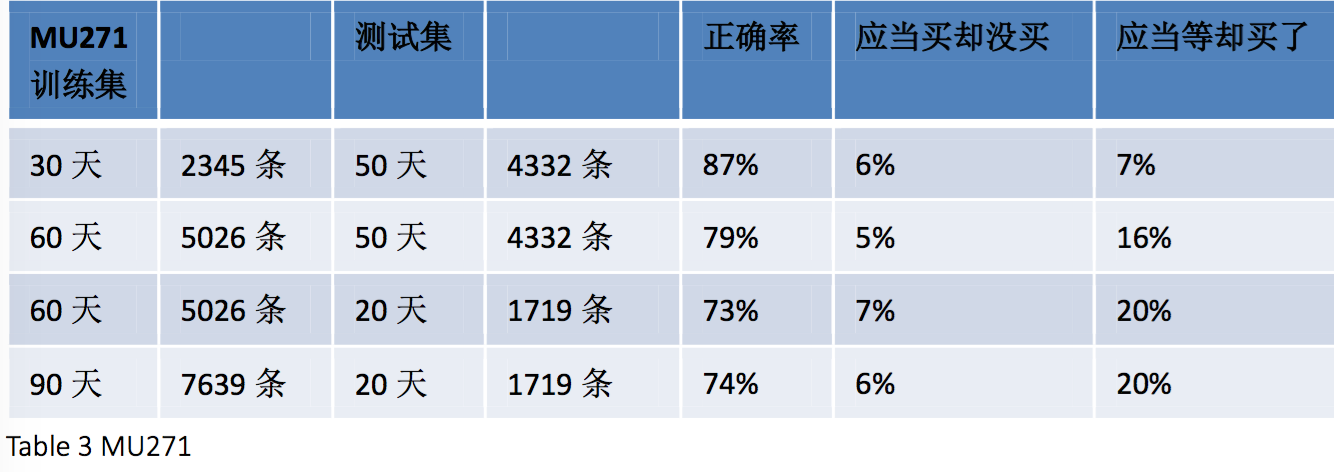 可以发现比较稳定的应该是70%以上这样的正确率。但这只是对MU271这个航班而言,为此我们选取了另外一个航班进行测试。
可以发现比较稳定的应该是70%以上这样的正确率。但这只是对MU271这个航班而言,为此我们选取了另外一个航班进行测试。
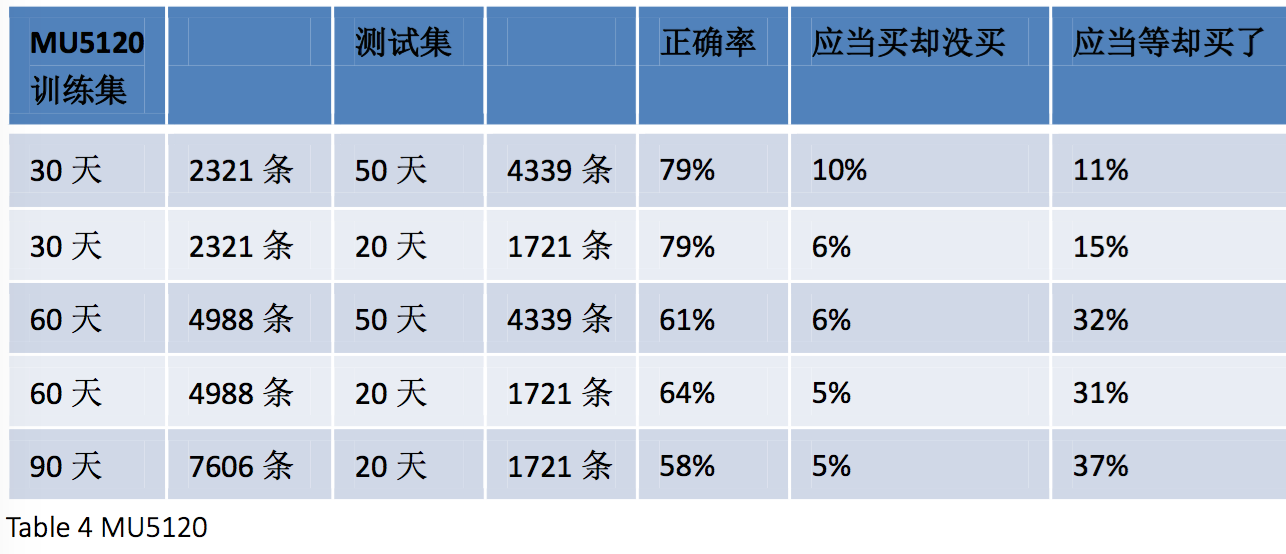 在这张结果汇总表里可以看到,对于MU5120的测试结果差别很大,低到50%多,高到有79%。显然同样的算法对于不同航班的效果不同,为了抹平这样的差距,我们尝试用十个航班混合的数据进行训练测试。
在这张结果汇总表里可以看到,对于MU5120的测试结果差别很大,低到50%多,高到有79%。显然同样的算法对于不同航班的效果不同,为了抹平这样的差距,我们尝试用十个航班混合的数据进行训练测试。
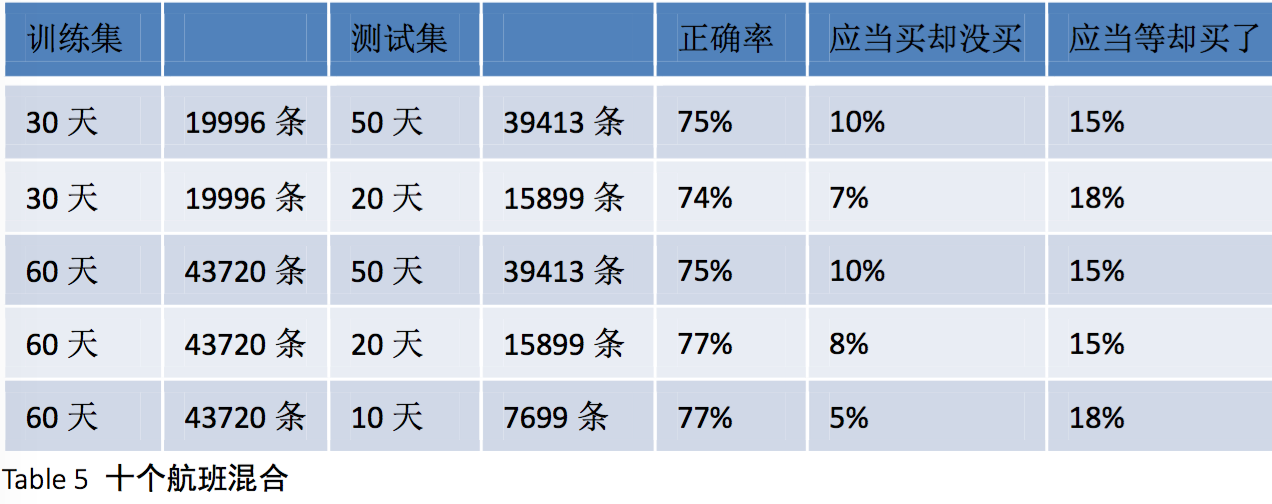 对于混合后的数据,预测的正确率显然比较稳定地维持在75%上下了。而观察错误的情况,“应当等却买了”的情况高于“应当买却没买”,这说明我们的算法对于未来更低价的出现可能性估计是比较保守。
对于混合后的数据,预测的正确率显然比较稳定地维持在75%上下了。而观察错误的情况,“应当等却买了”的情况高于“应当买却没买”,这说明我们的算法对于未来更低价的出现可能性估计是比较保守。
不足&疑问
-
无法用大规模数据建树。 由于决策树的算法使用的是开源包,而本身决策树最佳结点的选择就是遍历,这导致算法对于大数据的适用性很差。
-
仅尝试了基尼不纯度作为分类标准。 在以上的探索中,决策树构建仅使用了基尼不纯度,并未尝试信息熵来测试效果并和基尼不纯度进行对比。而且除了这两种之外,也未来得及考虑自己写分类标准函数的可能算法。
-
对于用户使用来说,什么样的训练集最合适?
-
只能预测买或不买,无法预测价格。